有关PostgreSQL物理备份、逻辑备份、PITR备份与块校验和功能的介绍&效果实验
本文节选自个人报告《实验报告-探究数据库系统与传统文件读写间的表现差异》
小插曲:写完报告一周后宇阙就崩了,当时崩了七个小时靠备份恢复恢复的用户数据,可以看到备份在数据库管理中的重要性()
注:由于宇阙图床不能直接外站访问因此图片丢了,可访问:https://www.yuque.com/stackoverflow-c1w4m/egpihd/wwh510w5syxyg90i 查看原文
参考资料
PostgreSQL 备份与恢复(第一章)-腾讯云开发者社区-腾讯云
Chapter 26. Backup and Restore
Postgresql的三种备份方式_pg库备份-CSDN博客
引言
在实际工程开发与维护过程中,数据表可能因多种原因出现损坏情况,从而对数据的持久性造成威胁。因此,对数据表进行损坏检查与损坏数据修复工作至关重要。PostgreSQL 官方文档中提供了三种备份方式([https://www.postgresql.org/docs/15/backup.html](https://www.postgresql. org/docs/15/backup.html)),分别为物理备份,逻辑备份与PRIP备份,同时提供了块数据校验技术以检测损坏数据的存在,有效保障了数据的一致性与持久性。物理备份
物理备份是最基础的数据库备份形式,即对数据库的实际存储文件进行复制操作,并将复制文件转移至外部存储设备中。采用Java手动管理数据文件读写的方式仅支持物理备份,在Windows系统下,可以使用类似于如下指令进行操作。1 | copy students.csv D:\data\ |
运行如上指令,我们可以在指定的文件夹中看到所备份的csv文件。

同样,该操作也可以应用于PostgreSQL系统中,通过查看PostgreSQL系统所指定的数据库文件地址,可以采用类似的方法进行复制备份,再通过覆盖的方式恢复文件数据,从而实现对数据的物理备份与恢复。
然而,无论是对于基于手动编程文件读写还是采用PostgreSQL系统实现数据管理,这种基于文件系统进行手动备份的操作对于数据文件复杂的情况下均较为繁琐,容易出现因手动复制操作错误造成备份数据的部分或全部损失,同时备份期间需暂停数据库系统的全部服务,亦不支持指定数据库的部分表数据进行备份。尽管可采用一致性快照等方式避免备份期间暂停数据库系统的服务,一致性备份仍无法上述解决全部问题。
在PostgreSQL系统中,提供了除文件系统级物理备份外,更为高效与可靠的备份方式。
逻辑备份
除物理备份外,PostgreSQL系统提供了逻辑备份方式以提高数据备份的效率与可靠性。逻辑备份使用pg_dump指令,需定期将数据库的结构与数据导出为SQL文件,在发生故障时再使用pg_restore指令将备份的SQL文件恢复至数据库中。PostgreSQL所提供的逻辑备份具有易于操作,无需停止数据库运行即可进行备份与恢复操作,备份文件跨版本兼容PostgreSQL系统的特点[4]
。但同时,逻辑备份存在数据库大时导入与导出效率低、只能实现数据部分恢复,无法修复损坏数据的缺陷。因此,实验对逻辑备份的相关特性进行了探究
基本逻辑备份操作
执行如下操作,创建数据表并导入数据1 | create |
执行备份操作
1 | pg_dump -d Test -f test.sql -U postgres -w |
可以在文件夹中看到所备份的test.sql文件

现在删除原数据表,执行恢复指令
1 | psql -d Test -U postgres -f test.sql |
可以在数据库中看到原表已被恢复
我们可以看到,采用逻辑备份可以较为方便地备份数据,当发生数据丢失时,可以将表恢复至备份时间点状态。但在逻辑备份时间点至故障发生时间点期间,如对表状态进行了修改操作,这部分修改操作将无法被恢复。因此,如采用逻辑备份进行备份,仍需承担部分数据丢失的风险,同时,逻辑备份也需要定期进行指令操作。
不同数据量下逻辑备份与恢复的速度测试
为探究逻辑备份在不同数据量下的导入与导出效率,实验在数据库中创建10张表格,分别截取huge.csv前一千、前一万、前10万、前100万、前1000万五组不同量级的数据作为单表数据,进行数据备份效率测试。同时,由于PostgreSQL系统支持采用并行转储加快大数据量的转储速度,实验设置了不开启并行转储、并行转出参数分别为2、4、8三组实验进行测试。本测试使用Windows Powershell控制台进行指令输入,使用Measure-Command关键字计算指令耗时
导入操作测试指令如下
1 | Measure-Command{pg_dump -d Test -f test.sql -U postgres} |
测试结果如下
| 单表 | 1k | 10k | 100k | 1M | 10M |
|---|---|---|---|---|---|
| 不并行转储 | 0.139s | 0.244s | 0.346s | 3.341s | 50.582s |
| 并行转储并行度2 | 0.220s | 0.257s | 0.606s | 4.413s | 40.757s |
| 并行转储并行度4 | 0.337s | 0.272s | 0.464s | 2.705s | 25.988s |
| 并行转储并行度8 | 0.361s | 0.371s | 0.473s | 2.038s | 17.951s |
采用同样方法,实验测试了仅在数据库中只有一张表的情况下,单表一万、10万、100万、1000万、一亿数据量的逻辑备份操作,实验结果如下
| 单表 | 10k | 100k | 1M | 10M | 100M |
|---|---|---|---|---|---|
| 不并行转储 | 0.123s | 0.249s | 0.365s | 3.282s | 51.384s |
| 并行转储并行度2 | 0.218s | 0.303s | 0.919s | 7.516s | 65.177s |
| 并行转储并行度4 | 0.297s | 0.365s | 0.904s | 7.937s | 65.485s |
| 并行转储并行度8 | 0.409s | 0.383s | 0.924s | 7.875s | 65.575s |
对上述实验中的转储文件进行恢复操作,操作指令如下
1 | Measure-Command{pg_dump -d Test -f test.sql -U postgres} |
1 | Measure-Command{psql -d Test -U postgres -f test.sql} |
数据库有10张表时数据导入速度测试
| 单表 | 1k | 10k | 100k | 1M | 10M |
|---|---|---|---|---|---|
| 不并行转储 | 0.140s | 0.207s | 0.754s | 12.629s | 152.794s |
| 并行转储并行度2 | 0.260s | 0.314s | 0.595s | 7.338s | 88.336s |
| 并行转储并行度4 | 0.329s | 0.307s | 0.478s | 5.290s | 69.012s |
| 并行转储并行度8 | 0.407s | 0.417s | 0.490s | 4.889s | 58.008s |
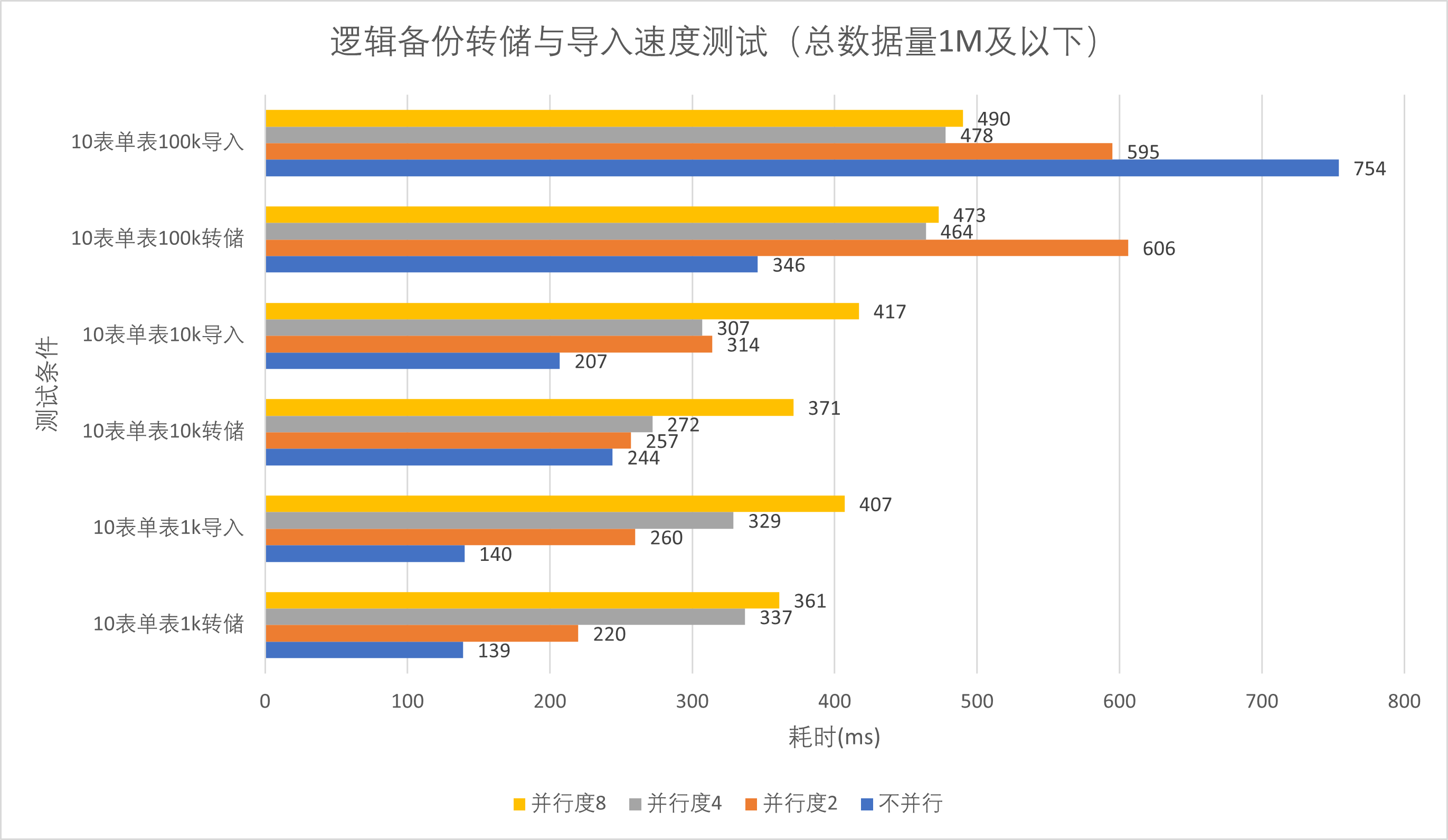
数据库仅有1张表时数据导入速度测试
| 单表 | 10k | 100k | 1M | 10M | 100M |
|---|---|---|---|---|---|
| 不并行转储 | 0.130s | 0.191s | 0.940s | 9.447s | 66.459s |
| 并行转储并行度2 | 0.262s | 0.457s | 1.057s | 11.022s | 148.581s |
| 并行转储并行度4 | 0.312s | 0.431s | 1.043s | 10.165s | 145.385s |
| 并行转储并行度8 | 0.454s | 0.432s | 1.048s | 11.199s | 147.507s |
对上述测试结果进行数据处理绘制表格,结果如下
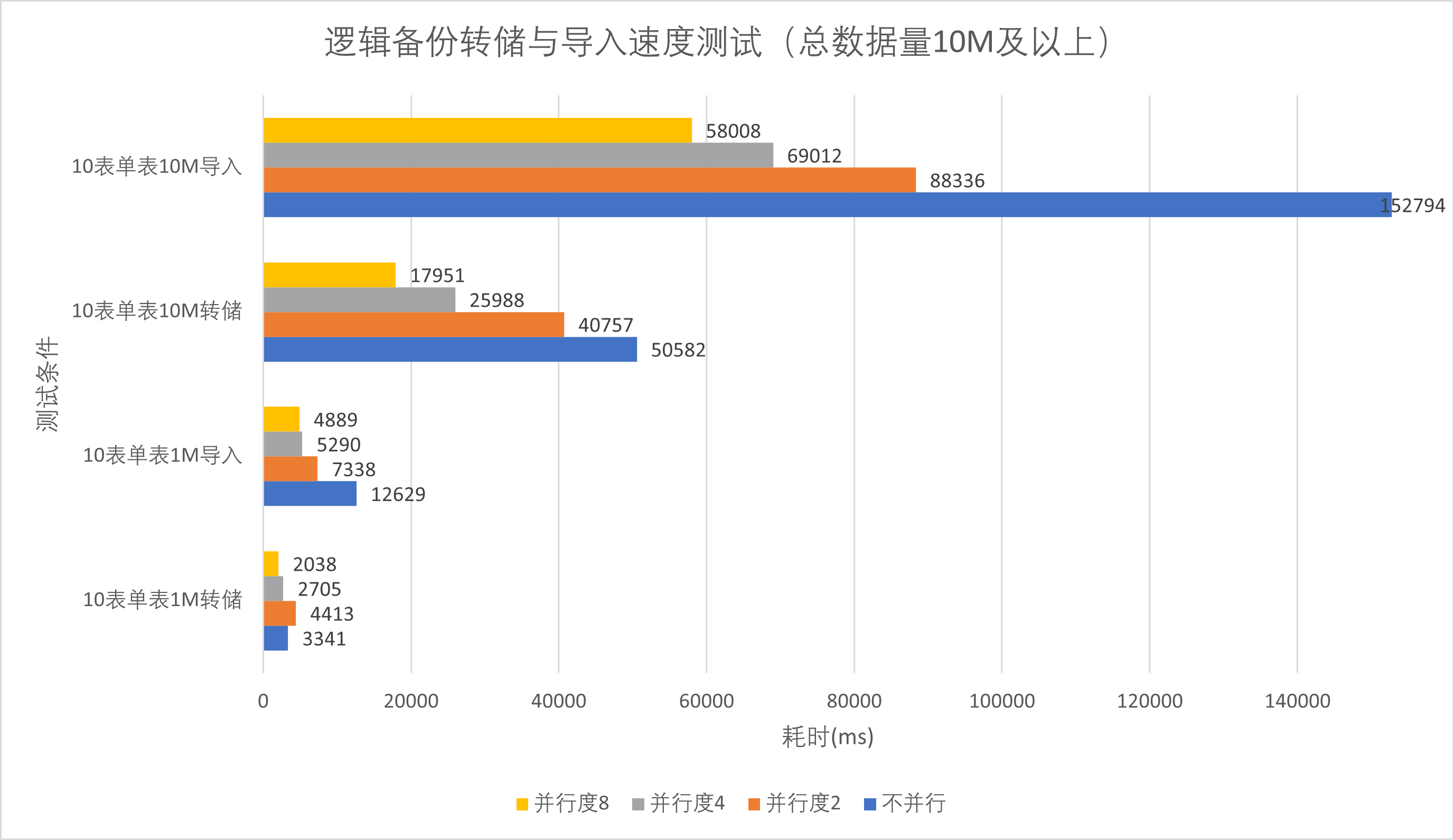
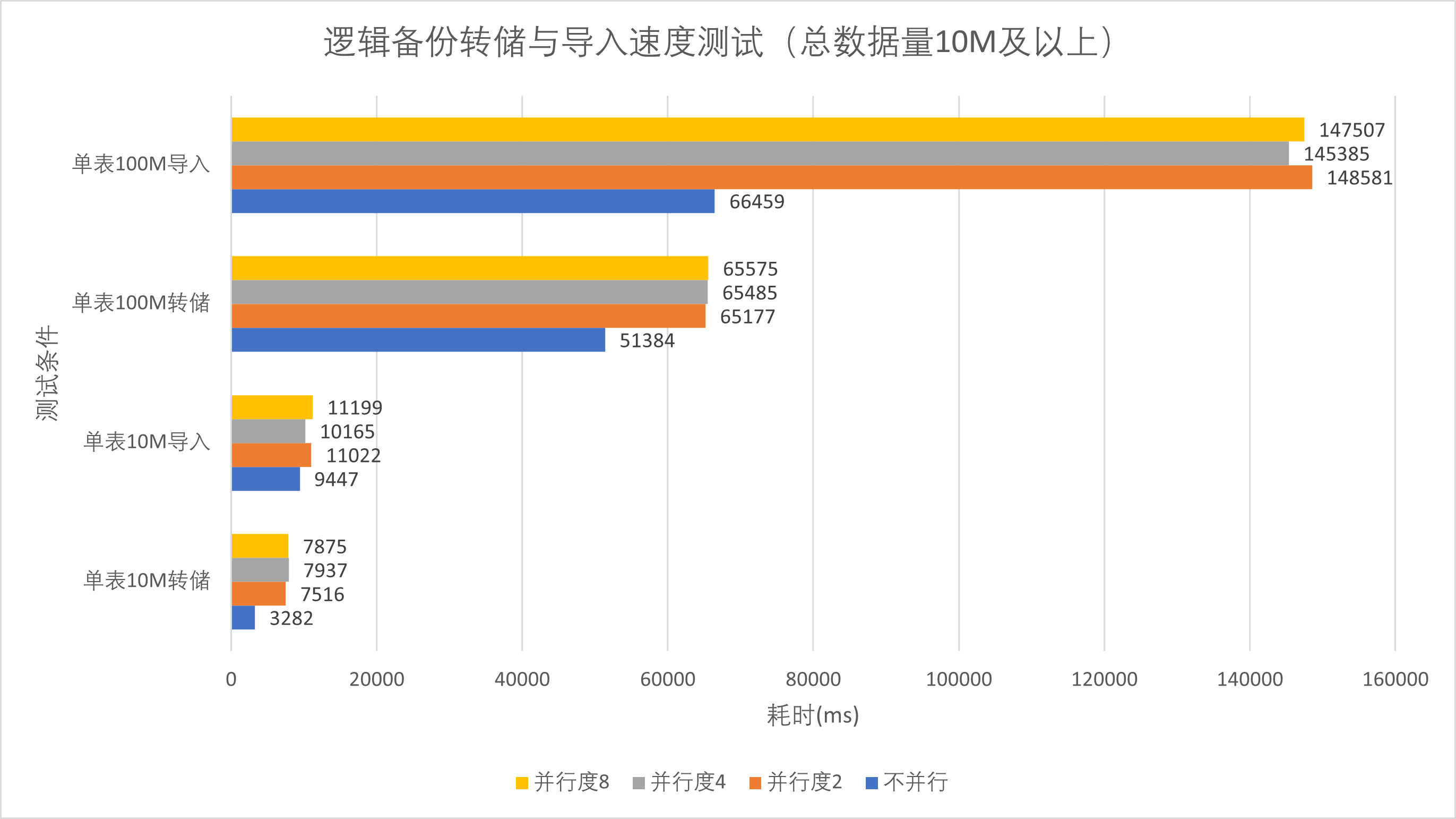
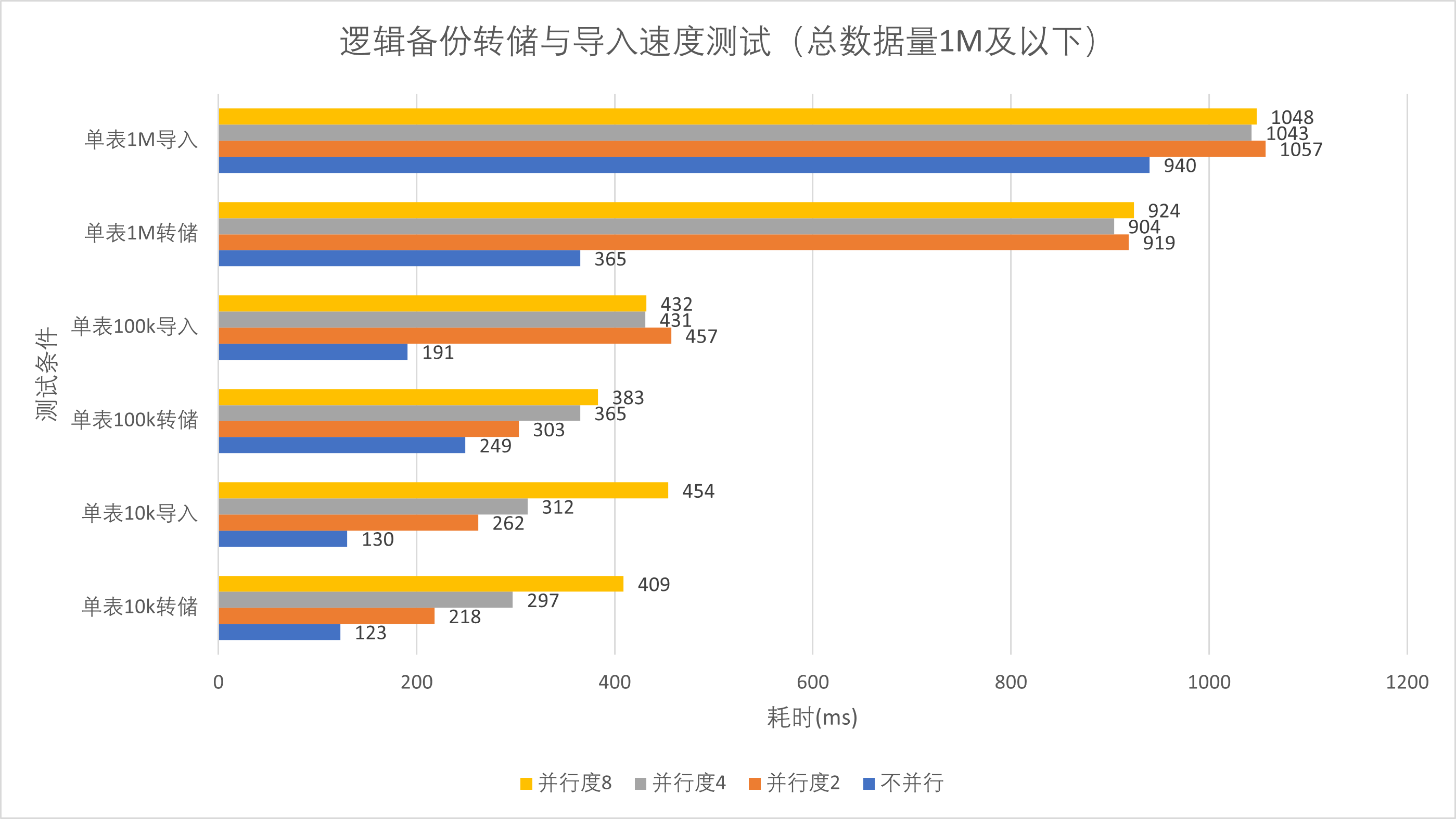
分析上述数据,我们可以由结果图1、3直观的看到,对于多表数据库,当数据量较大时,测试组中并行转储度越高,转储与恢复的速度越快。但对于单表数据库,开启并行转储会显著降低转储与恢复速度。这是由于PostgreSQL的并行转储与恢复操作的粒度是以表为单位的,对于多表数据库可以并行处理以加快转储恢复速度,但PostgreSQL不能对单张表进行并行转储或并行导入操作,反而会因为多线程开销降低转储与恢复速度。
同时我们由图2、4可以发现,当数据量较小时(总数据量1M条(24Mb)及以下),两种方式转出时间均较短(小于1.1s),对多表数据库的并行操作并未显著提高并行转储与导入效率,反而可能降低。
因此,对于数据量较小,数据库表数较少的数据库,采用串行转储方式更加简单高效。而对于*
数据量较大的数据库,采用并行处理能够显著的提高转储速度*。与此同时,对于多表大型数据库,并行转储设置的并行参数的设置应参考主机配置与库表总数,
在主机配置许可的范围内尽可能增加并行度,从而提高转储与恢复效率。
逻辑备份操作对数据库运行影响测试
在线上环境中,数据库备份与转储的过程可能会对数据库当前运行的服务造成影响,从而可能提高数据备份操作的潜在成本,本研究对此设置实验进行探究。实验huge.csv文件作为唯一表的测试数据,对单表数据库进行逻辑备份操作,同时在备份运行期间在其它连接中进行sql语句测试(每条sql语句作为独立事务运行),测试sql语句如下
1 | select count(*) from students where id between 1145 and 1926; |
在备份运行期间执行sql测试语句,执行结果如下
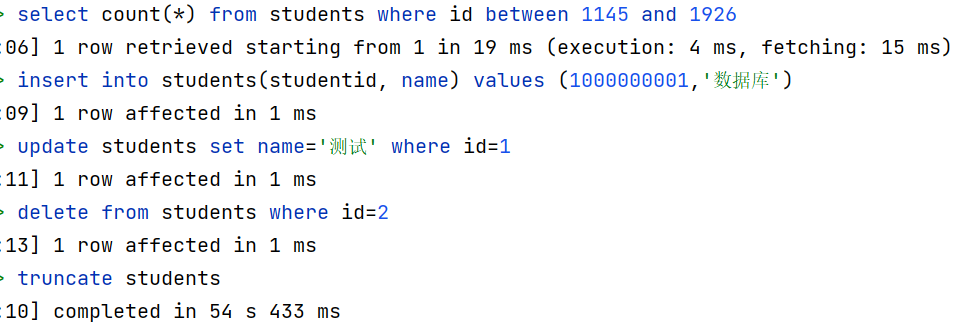
可以看到在备份期间所执行的增删改查语句并未受到显著影响,而对表本身操作的第五条sql语句执行耗时异常,这是由于备份期间备份线程对所需备份的表添加了访问锁(Access
Shared Lock)[4]
,该锁不会阻塞对表的DML语句操作与DQL语句查询,但是会阻塞对表定义的DDL语句操作,因此,在上述操作语句中,仅有truncate语句运行耗时过长,即该语句对表操作被逻辑备份所创建的表访问锁阻塞。
尝试对该表进行恢复导入,观察导入后的数据表
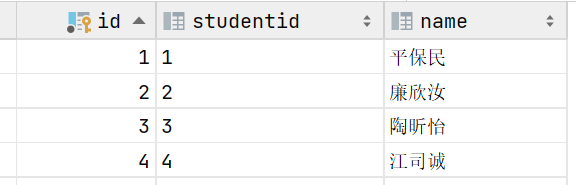
我们可以发现,在备份期间对数据库进行的DML操作并未生效。这是由于PostgreSQL采用了MVCC机制实现数据库的并发控制,逻辑备份指令运行时,会开启事务并创建运行指令时刻的数据库快照,该事务为可重复读隔离级别,备份事务将会读取历史快照数据进行备份,从而避免了对数据库加锁而阻塞DML操作。因此,在备份事务开启后进行的DML操作不会被备份,同时也不会影响逻辑备份事务的备份操作。
因此实验发现,在逻辑备份运行期间,对数据库表的DDL操作会受到阻塞
,这是由于备份事务开启时对所有所需备份表均添加了表访问锁,在实际维护中,可以在**备份数据库期间添加-t参数指定所需备份的表
**[4]
。其次,PostgreSQL采用MVCC机制实现备份事务对表的可重复读,在备份期间避免了对DML语句的运行进行阻塞,同时,在备份事务运行期间与运行结束后对数据库数据进行的操作不会被备份事务所备份。
PITR备份
为实现对事务模型的支持,PostgreSQL数据库系统采用预写日志(WAL)以实现对事务的回滚操作。连续归档和时间点恢复备份技术(PITR)便是基于时间点与WAL日志归档的备份恢复技术。在发生数据损坏时,PostgreSQL会依据基础备份与WAL日志对数据进行恢复,能够有效将数据内容恢复至故障发生前的最后有效数据,从而避免了备份点至故障发生点期间的数据丢失。实验对PITR技术的有效性进行了测试。PITR备份有效性实验
实验采用huge.csv前1000行数据作为表数据进行模拟实验,实验过程如下- 首先,采用PITR数据备份技术需开启WAL日志归档,以长期存储WAL日志信息
在postgresql.conf中修改如下配置,随后重启服务器
1 | wal_level = archive |
- 执行如下指令为整个数据库集簇创建一个基础备份
1 | pg_basebackup -D E:\data\202310120100 -Ft -z -P -U postgres -Xs |
可以在数据库中看到基础备份文件

- 在基础备份创建完成后,执行如下测试语句,模拟对数据库数据的操作
1 | select count(*) from students where id between 1145 and 1926; |
- 对数据库文件进行操作,模拟数据库文件的损坏
调用如下指令,查询数据库表文件的存储位置,并删除该存储文件
1 | select pg_relation_filepath('students'); |
运行select语句测试,可以看到数据库抛出异常

- 开始采用连续归档备份对数据进行恢复
- 清空data路径下无用的数据目录文件与日志文件
- 将基础备份文件拷贝到数据目录下并解压,执行如下解压指令
1 | tar -zxvf base.tar.gz |
3. 在postgresql.conf中添加恢复指令参数,添加如下配置
1 | restore_command = 'copy "E:\\data\\%f" "%p"' |
4. 创建recovery.signal文件,可以在其中指定所需恢复到的时间点参数
5. 启动服务器,此时服务器开始进行恢复工作
6. 回到数据表中,我们检查students数据表中的数据信息
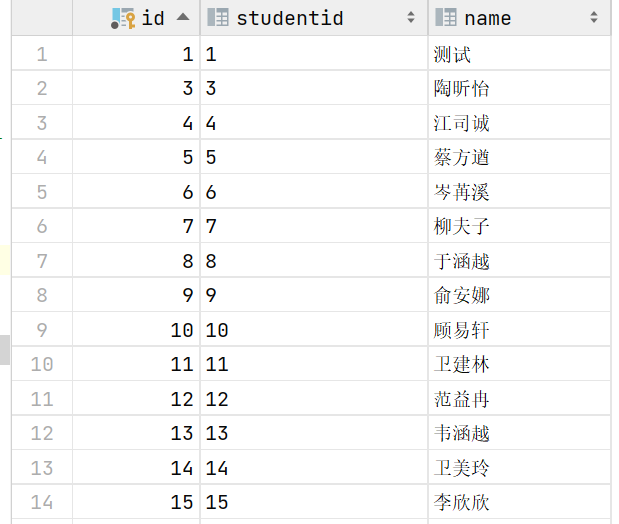
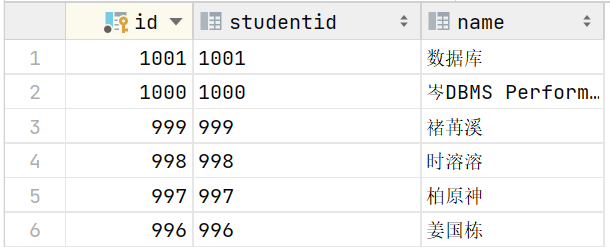
可以发现所有的数据都被成功恢复,包括在备份点后进行的数据操作也被成功恢复。
根据上述实验,我们可以看到,采用PITR对数据库系统进行备份能够*
*有效地将数据恢复至数据库运行故障前的最后有效时刻,从而最大程度地保留了有效数据,有效保障了数据的一致性与持久性
**
。查阅PostgreSQL官方文档,我们同时发现,PITR备份运行时无需对数据库添加任何级别的锁,这是由于PostgreSQL系统在备份开始前先执行了一次检查点将数据刷入磁盘中,随后采用流复制技术从磁盘中复制数据,且在备份结束前阻止再次执行检查点刷入数据,从而在不阻塞数据库服务的情况下保证了备份数据的一致性。同时,pg_basebackup默认会将检查点所需I/O操作分散在一段时间上,从而避免集中I/O操作占用大量数据库性能资源影响数据库的正常服务。最后,除将数据恢复至崩溃前最后时刻外,
PITR备份还支持将数据回滚至指定的时间
,能够有效在开发过程中不慎写入脏数据后对数据进行恢复,有效保障了数据库的一致性。
但是,PITR备份亦存在**数据备份与恢复操作较繁琐,存储文件体积较大,无法指定单个数据库或表进行备份的缺点
**
,同时,相较于逻辑备份,PITR备份所生成的数据间具有关联性,若备份文件损坏,则难以从中提取出有效数据。最后,PITR备份方式不具备跨版本与跨数据库能力,因此,使用逻辑备份或PITR备份的选择需参考现实开发与运营的需要。
块数据校验和
除数据的直接丢失或无法解析可能对数据一致性与持久化造成威胁外,数据库数据也可能会出现块损坏等数据异常,出现行损坏、信息丢失或重复,由于此类小部分数据的损坏不会直接造成数据库的运行异常,因此该故障往往十分隐蔽,难以被开发人员及时发现,因此对数据一致性造成了较大威胁。对于高价值低容差的数据存储场景,需采用某种手段对数据的正确性进行校验,PostgreSQL系统提供了块数据校验和的技术以实现此需求。块数据和校验技术通过数据校验算法在对数据库进行修改操作时计算所存储数据块的校验和并保存,随后在每次读取该块时重新计算数据库校验和与已有校验和进行比较,以检验数据块是否损坏。实验对块数据校验和技术的有效性进行测试。
块数据校验和有效性实验
实验基于students表结构进行修改作为测试表,对块数据校验和的有效性进行测试,实验过程如下- 暂停数据库运行,开启块数据校验和,运行如下指令
1 | pg_checksums -D "C:\Program Files\PostgreSQL\15\data" -e |
- 恢复数据库运行,创建students表并向其中插入测试数据
1 | create table students |
- 模拟数据库表文件发生数据损坏
- 运行pg_relation_filepath函数查询数据库表文件的存储位置
- 查看该页文件的内容,我们可以看到该数据表存储文件大小为8k,包含有一个数据块
3. 复制该块数据并追加至该块末尾。在Windows系统下,实验选择该数据复制该数据表文件(41178_1),执行如下指令,实现追加复制数据块。
1 | Get |
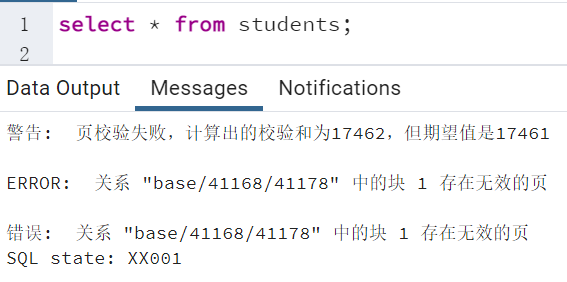
- 执行select语句测试,发现PostgreSQL系统提示数据块页校验失败,表明数据库系统已检测非法数据
- 停用数据库,执行pg_checksums检查数据页是否存在错误,执行如下代码
1 | pg_checksums |

我们可以发现,pg_checksums检出了块数据异常的存在与异常存在位置。
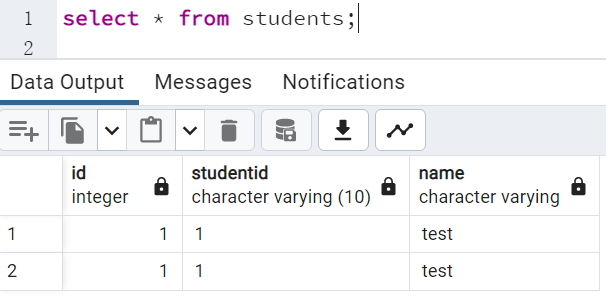
- 为验证数据块校验和的有效性,我们此时关闭checksums功能,进行查询测试
1 | pg_checksums -D "C:\Program Files\PostgreSQL\15\data" -d |
再次执行select语句,我们发现查询结果包含了错误数据2,没有满足数据一致性需求。
综合上述实验实验发现,开启块数据校验和能够及时有效地检出数据表中存在的数据损坏,从而在更高程度上保障了数据一致性与数据持久化。
块数据校验和性能影响实验
实验采用huge.csv前1万,前100万,前1000万与全表1亿数据,针对students表结构创建频繁查询文件select2.sql,对表进行10万次主键查询,比较开启块数据和校验与不开启块数据和校验对数据块频繁查询的性能影响,实验结果如下。| 数据量 | 10k | 1M | 10M | 100M |
|---|---|---|---|---|
| 不开启块数据校验和 | 16.855s | 17.750s | 18.209s | 18.685s |
| 开启块数据校验和 | 17.471s | 19.263s | 19.598s | 21.181s |
对上述数据绘制表格进行分析,结果如下
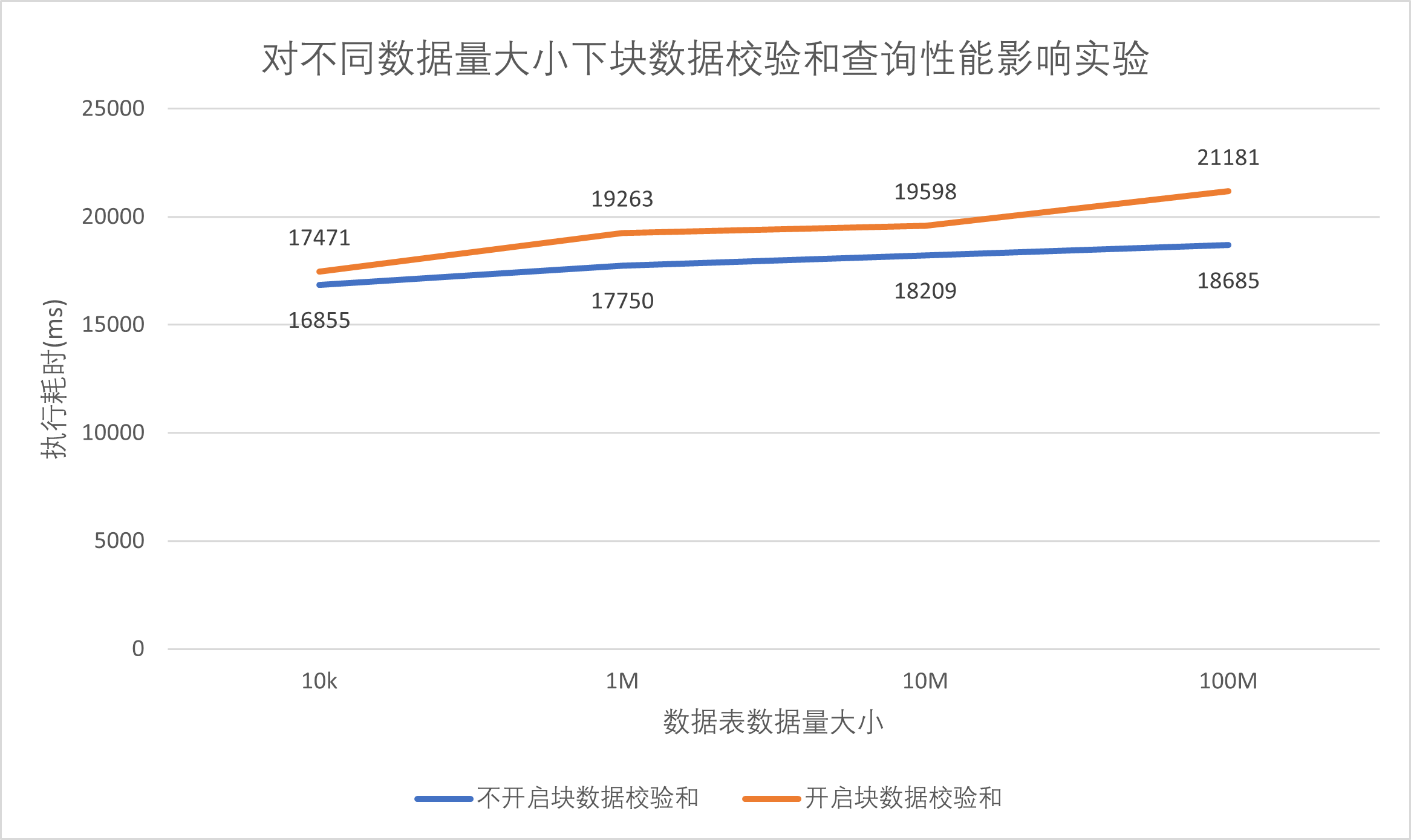
由上述结果我们发现,开启数据校验和后数据查询操作所消耗的时间略高于未开启条件下的耗时,但不同数据量数据表执行相同频繁查询的
时间差距基本于10%以内,表明块数据校验和对数据块查询性能存在轻微的影响
总结
综合上述实验我们发现,对于PostgreSQL所提供的三种备份方式,在实际使用中往往不提倡采用文件系统级的物理备份,而是采用更为实用有效的逻辑备份与PITR备份技术。逻辑备份能够有效地将数据备份至外部存储设备,其执行简单高效,且可以采用并行处理的方式提高多表大数据库的转储导入效率,但其需要执行定期备份,无法将数据精确的恢复至故障发生前的最后有效数据。
而采用PITR备份技术能够有效地将数据恢复至故障发生前的最后有效时刻,同时也支持将数据回滚至指定的时间点,从而在更高的程度上保障了数据的一致性,但是,PITR备份亦存在操作较繁琐,存储文件体积较大,无法指定单个数据库或表进行备份,难以从中提取出有效数据,不具备跨版本与跨数据库能力等缺点。
因此,在实际的开发过程中,可以参考对数据完整性与一致性的实际需要,结合逻辑备份与PITR备份技术,在开PITR备份的同时,定期更新基础备份点与进行逻辑转储备份。
最后,对于数据价值较高,数据一致性需求较高的场景,还可以通过开启块数据校验和功能,以从更高程度上保障数据的一致性。